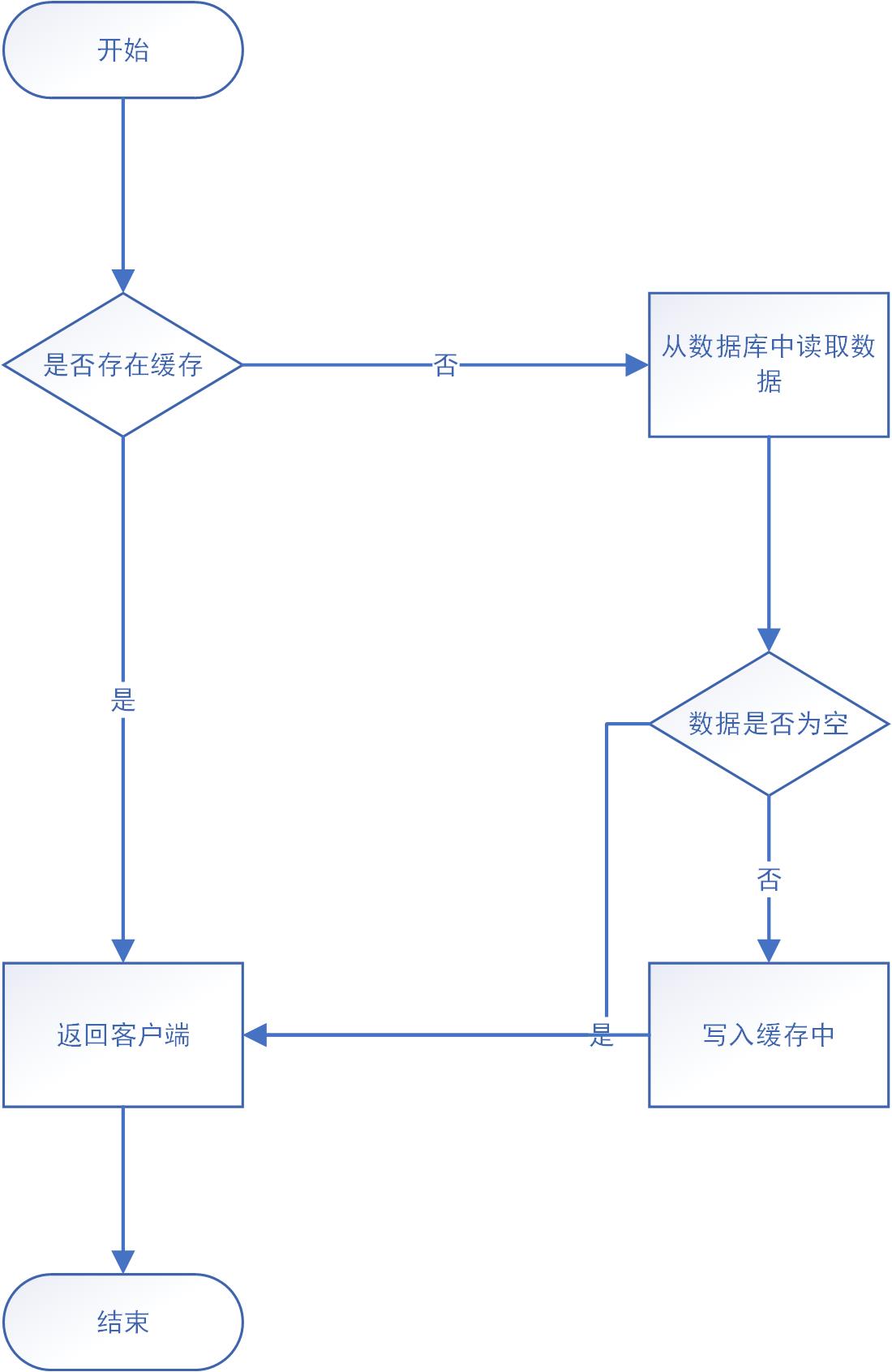
在当前环境下,分布式架构已经被广泛使用,其中缓存由于其高并发和共性能的特点,在分布式系统中频繁被使用,在使用缓存过程中,对于读取缓存,通常都是按照下图中的流程来进行业务操作的。
更新策略
首先,从理论上来说,给缓存设置过期时间,是保证最终一致性的解决方案。这种方案下,我们可以对存入缓存的数据设置过期时间,所有的写操作以数据库为准,对缓存操作只是尽最大努力即可。也就是说如果数据库写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存。因此,接下来讨论的思路不依赖于给缓存设置过期时间这个方案。主要讨论三种更新策略:
- 先更新数据库,再更新缓存
- 先删除缓存,再更新数据库
- 先更新数据库,再删除缓存
先更新数据库,再更新缓存
这个方案,是普遍被反对的,原因主要有如下两点:
- 线程不安全,假如现在存在请求A和请求B进行更新操作,那么可能会出现
- 请求A更新了数据库
- 请求B更新了数据库
- 请求B更新了缓存
- 请求A更新了缓存
- 从业务角度考虑,存在如下两点情况:
- 如果是一个写数据库场景比较多,而读数据库场景比较少的业务需求,采用这种方案就会导致,数据压根还没有读到,缓存就被频复的更新,浪费性能
- 如果写入数据库的值,并不是直接写入缓存,而是经过一系列复杂的计算再存入缓存,那么,每次写入数据库后,都要计算写入缓存的值,无疑是浪费性能的,显然,删除缓存更为合适。
先删除缓存,再更新数据库
该方案同样会导致数据不一致,原因是一个请求A进行更新操作,一个请求B进行查询操作,那么会出现如下情形:
- 请求A进行写操作,删除缓存
- 请求B查询发现缓存不存在
- 请求B去数据库中查询得到旧值
- 请求B将旧值写入缓存
- 请求A将新值写入数据库
意思情况就会导致不一致的情形出现,而且,如果不采用缓存设置过期时间策略,该数据将永远都是脏数据。那么,该如何解决这个问题呢?可以采用延时双删策略,思路就是:
- 先删除缓存
- 再写入数据库(这两步和原来一样)
- 再休眠1秒,再次删除缓存
这么做可以将1秒内产生的缓存脏数据再次删除。当然这个1秒可以在不同的业务场景中设置不同的值。只需要确保读请求B结束,写请求A可以将读请i去B造成的脏数据删除掉就行。
先更新数据库,再删除缓存
首先,国外提出了一个缓存更新套路,名为《Cache-Aside pattern》,其中就指出,
- 失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
- 命中:应用程序从cache中取数据,取到后返回。
- 更新:先把数据存到数据库中,成功后,再让缓存失效。
另外,知名社交网站facebook也在论文《Scaling Memcache at Facebook》中提出,他们用的也是先更新数据库,再删缓存的策略。这个方案相比较 先删除缓存,再更新数据库 中使用到的延时双删策略,少了第一次删除缓存的操作,可以极大地避免因为更新请求删除缓存后读请求产生脏数据的情况。只有在如下情形下会有只能脏数据产生:
- 一个请求A进行查询操作,一个请求B进行更新操作
- 缓存刚好失效
- 请求A查询缓存无数据,查询数据库,得到一个旧值
- 请求B将新值写入数据库
- 请求B删除缓存
- 请求A将查询到的旧值写入到缓存中
按照上面的顺序的确是会产生脏数据,但是上述情况的发生必然要满足4的写步骤比3中的读耗时更短,才有可能使得5比6先发生,(一旦6比5先发生也就不会产生脏数据)。可是,数据库的读操作是比写操作要更快的,所以步骤4耗时比步骤3短这一情形很难出现。