Mysql
事务
- 事务的特性ACID
隔离级别

产生死锁的四个必要条件:
(1) 互斥条件:一个资源每次只能被一个进程使用。 (2) 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。 (3) 不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。 (4) 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
索引
索引的类别
- Primary Key(聚集索引):InnoDB存储引擎的表会存在主键(唯一非null),如果建表的时候没有指定主键,则会使用第一非空的唯一索引作为聚集索引,否则InnoDB会自动帮你创建一个不可见的、长度为6字节的row_id用来作为聚集索引。
- 单列索引:单列索引即一个索引只包含单个列
- 组合索引:组合索引指在表的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用。使用组合索引时遵循最左前缀集合
- Unique(唯一索引):索引列的值必须唯一,但允许有空值。若是组合索引,则列值的组合必须唯一。主键索引是一种特殊的唯一索引,不允许有空值
- Key(普通索引):是MySQL中的基本索引类型,允许在定义索引的列中插入重复值和空值
- FULLTEXT(全文索引):全文索引类型为FULLTEXT,在定义索引的列上支持值的全文查找,允许在这些索引列中插入重复值和空值。全文索引可以在CHAR、VARCHAR或者TEXT类型的列上创建
- SPATIAL(空间索引):空间索引是对空间数据类型的字段建立的索引,MySQL中的空间数据类型有4种,分别是GEOMETRY、POINT、LINESTRING和POLYGON。MySQL使用SPATIAL关键字进行扩展,使得能够用于创建正规索引类似的语法创建空间索引。创建空间索引的列必须声明为NOT NULL
索引的优缺点
- 优点
- 使用索引可以大大加快 数据的检索速度(大大减少检索的数据量), 这也是创建索引的最主要的原因。
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
- 缺点
- 创建索引和维护索引需要耗费许多时间。当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低 SQL 执行效率。
- 索引需要使用物理文件存储,也会耗费一定空间。
索引的底层数据结构
- Hash表
- 通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据(接近 O(1))。
- B+树
- 多路平衡查找树 ,B+ 树是 B 树的一种变体。B 树和 B+树中的 B 是 Balanced (平衡)的意思。
- B 树& B+树两者有何异同呢?
- B 树的所有节点既存放键(key) 也存放 数据(data),而 B+树只有叶子节点存放 key 和 data,其他内节点只存放 key。
- B 树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
- B 树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而 B+树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
性能优化
执行计划
id SELECT查询的序列标识符;id越大的越先执行,相同id大小时从上到下执行
select_type SELECT关键字对应的查询类型;
table 用到的表名
partitions 匹配的分区,对于未分区的表,值为 NULL
type 表的访问方法;描述了查询是如何执行的。所有值的顺序从最优到最差排序为:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
possible_keys 可能用到的索引; MySQL 执行查询时可能用到的索引。如果这一列为 NULL ,则表示没有可能用到的索引
key 实际用到的索引;列表示 MySQL 实际使用到的索引。如果为 NULL,则表示未用到索引。
key_len 所选索引的长度
ref 当使用索引等值查询时,与索引作比较的列或常量;
rows 预计要读取的行数;数值越小越好。
filtered 按表条件过滤后,留存的记录数的百分比;一般越高越好
Extra 附加信息;
Using filesort:在排序时使用了外部的索引排序,没有用到表内索引进行排序。
Using temporary:MySQL 需要创建临时表来存储查询的结果,常见于 ORDER BY 和 GROUP BY。
Using index:表明查询使用了覆盖索引,不用回表,查询效率非常高。
Using index condition:表示查询优化器选择使用了索引条件下推这个特性。
Using where:表明查询使用了 WHERE 子句进行条件过滤。一般在没有使用到索引的时候会出现。
Using join buffer (Block Nested Loop):连表查询的方式,表示当被驱动表的没有使用索引的时候,MySQL 会先将驱动表读出来放到 join buffer 中,再遍历被驱动表与驱动表进行查询。
当 Extra 列包含 Using filesort 或 Using temporary 时,MySQL 的性能可能会存在问题,需要尽可能避免。
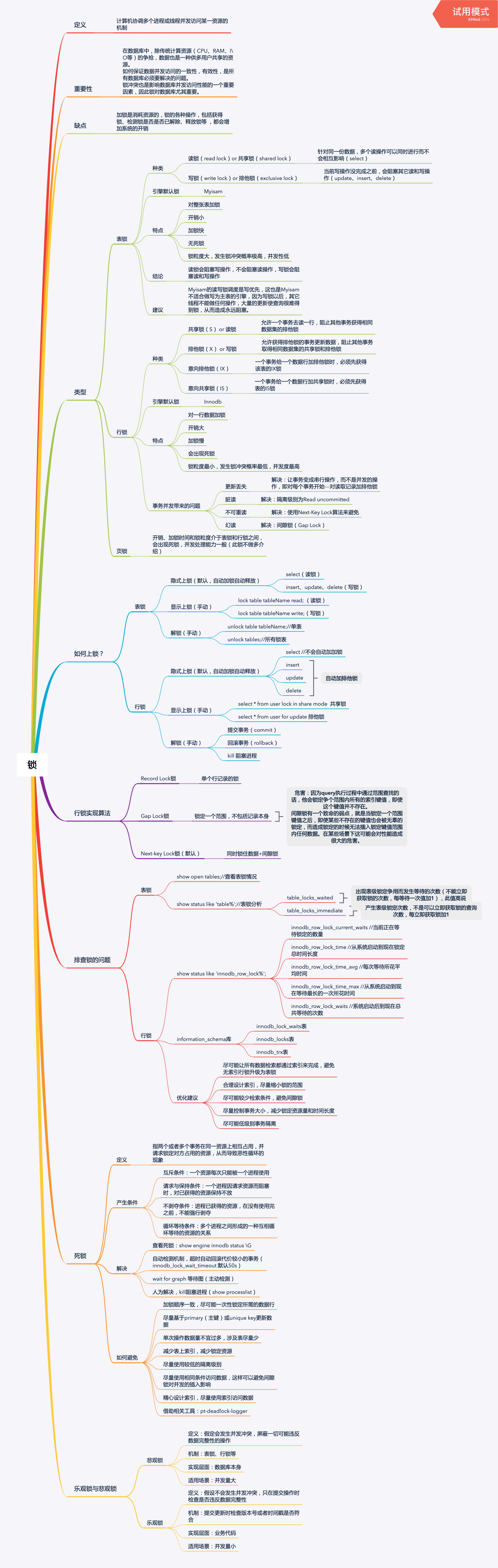
行锁&表锁
MySQL三大日志(binlog、redo log和undo log)
MySql Mvcc
MVCC的机制? MVCC怎么解决幻读问题的? 临键锁的范围是怎么确定的?
- 索引的基本原理
- Mysql聚簇和非聚簇索引的区别
- Mysql索引的数据结构,各自优劣
- 索引设计的原则?
- InnoDB存储引擎的锁的算法
- 关心过业务系统里面的sql耗时吗?统计过慢查询吗?对慢查询都怎
- 么优化过?
- 事务的基本特性和隔离级别
- 什么是MVCC
- 分表后非sharding key的查询怎么处理,分表后的排序?
- Mysql主从同步原理
- 简述MyISAM和InnoDB的区别
- 简述Mysql中索引类型及对数据库的性能的影响
- Explain语句结果中各个字段分表表示什么
- 索引覆盖是什么
- 最左前缀原则是什么
- Innodb是如何实现事务的
- B树和B+树的区别,为什么Mysql使用B+树
- Mysql锁有哪些,如何理解
- Mysql慢查询该如何优化?